
Eu gosto muito do VS Code. O editor de códigos da microsoft é muito versátil, permitindo o uso com diversas linguagens de programação ou criando ambientes completos de determinada “stack” tecnológica. Extremamente customizável, podemos usar temas para mudar a aparência do editor e extensões para acrescentar ou modificar funcionalidades ao VSCode.
Quando eu entrei no desafio de análise de dados com python e pandas no bootcamp de Data Science da digital innovation one, procurei uma maneira de usa-lo para editar os notebooks usados na tarefa. Foi justamente através das extensões que eu integrei ele a plataforma jupyter, o que permitiu usar as funções integradas ao VSCode(como o versionamento GIT). Com esse artigo mostrarei como configurar e transformar o editor da microsoft em um ambiente eficiente para editar nossos notebooks do pandas =D
O pré-requisito para usarmos os notebooks do jupyter no VSCode é termos o jupyter instalado , já que ao rodá-los nos conectamos com o kernel da aplicação. No meu caso eu já possuía o jupyter lab instalado, caso tu não tenhas pode baixar o anaconda (que é o recomendável) através deste link: Anaconda ou usar o gerenciador de pacotes do python, abrindo o terminal e rodando o comando
pip install jupyterlab
Com o jupyter instalado e configurado abrimos o VSCode e e instalamos a extensão que permite a integração com o jupyter e o uso do kernel. Basta entrar no marketplace das extensões e procurar por “jupyter”
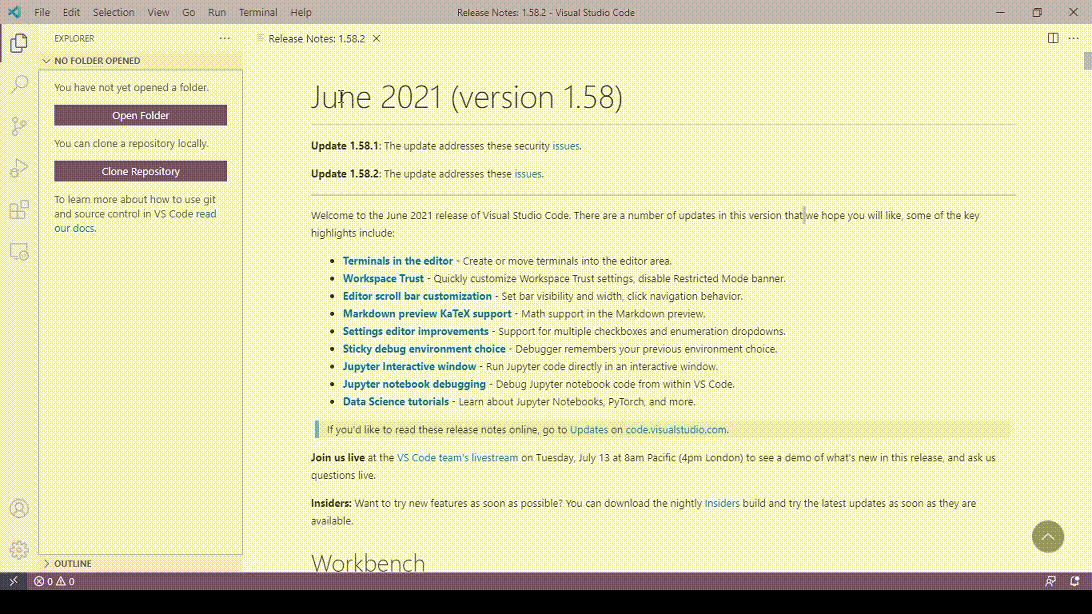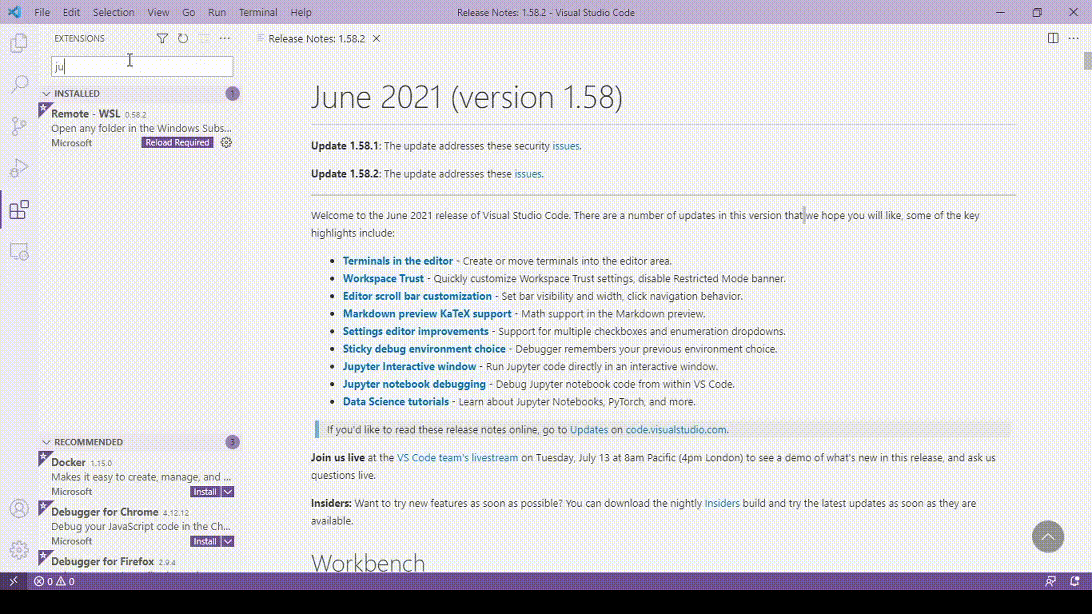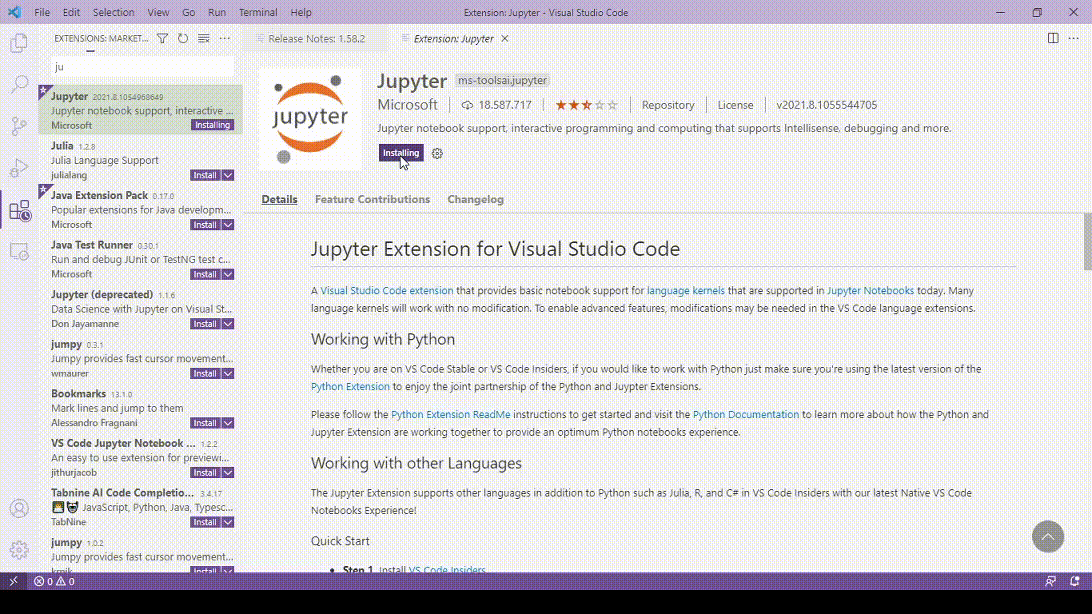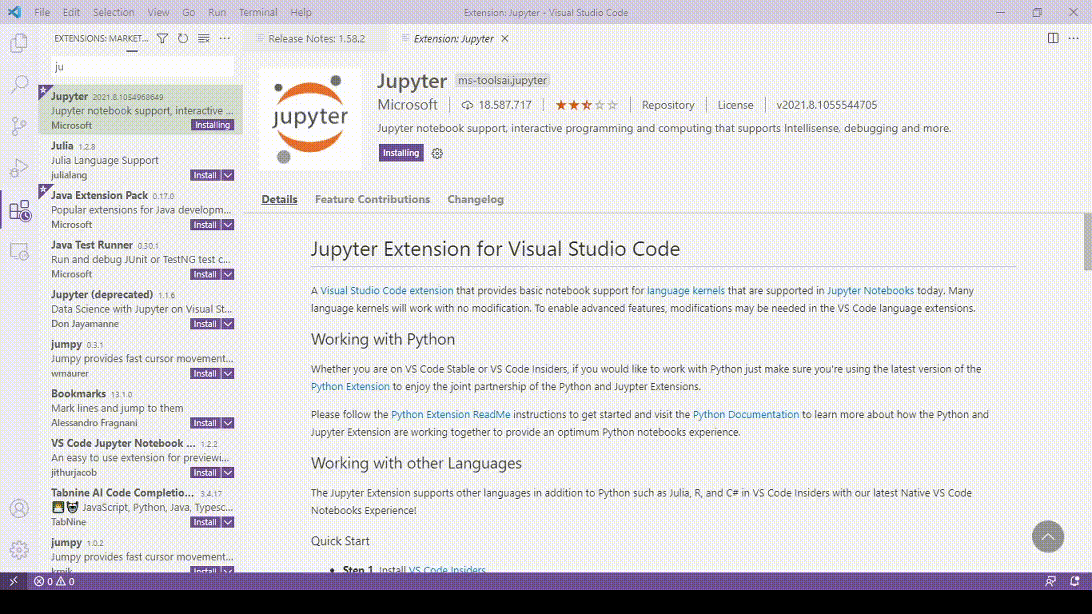
Com tudo instalado basta clonar o repositório(eu já havia criado um fork do repositório do desafio), com a conta do github logada é possível listar todos os repositórios disponíveis. Caso queira podes colocar a URL direto.
Depois que todo o repositório baixou, basta abrir o notebook. Na parte superior temos as opções disponíveis.

- “code” e “markdown “ são as opções para adicionar novos blocos no notebook.
- “run all” executa todo os blocos.
- “clear outputs” limpa todas as saídas
- “restart” e “interrupt” controlam a execução.
Na primeira vez que executar, abre a opção pedir selecionar o kernel- escolha o do “conda”.
Como no ambiente “normal” do jupyter, cada bloco tem seu controle de execução assim como o atalho “shift + enter”
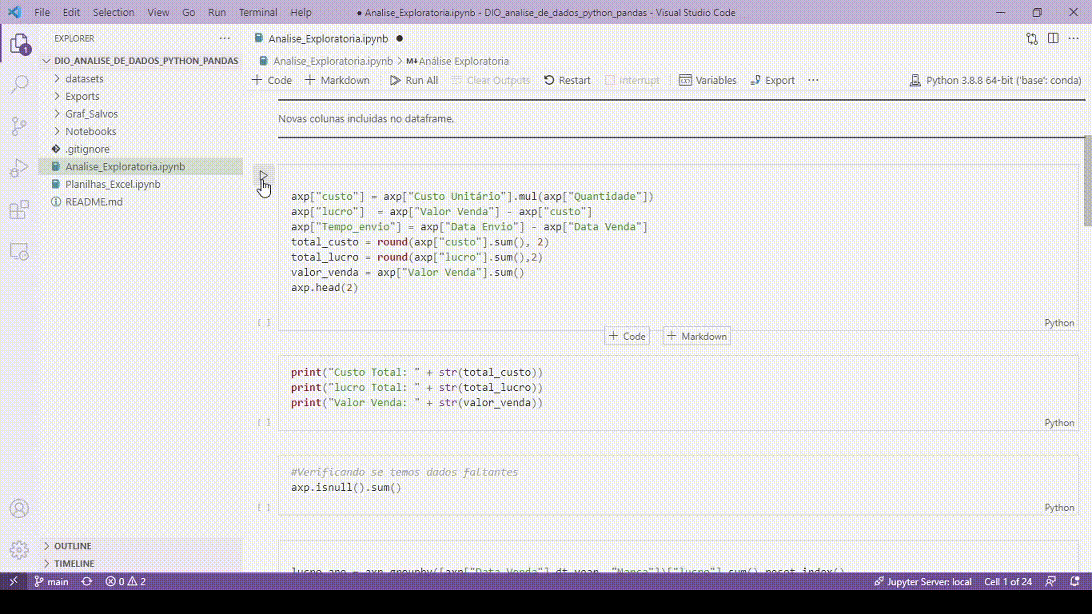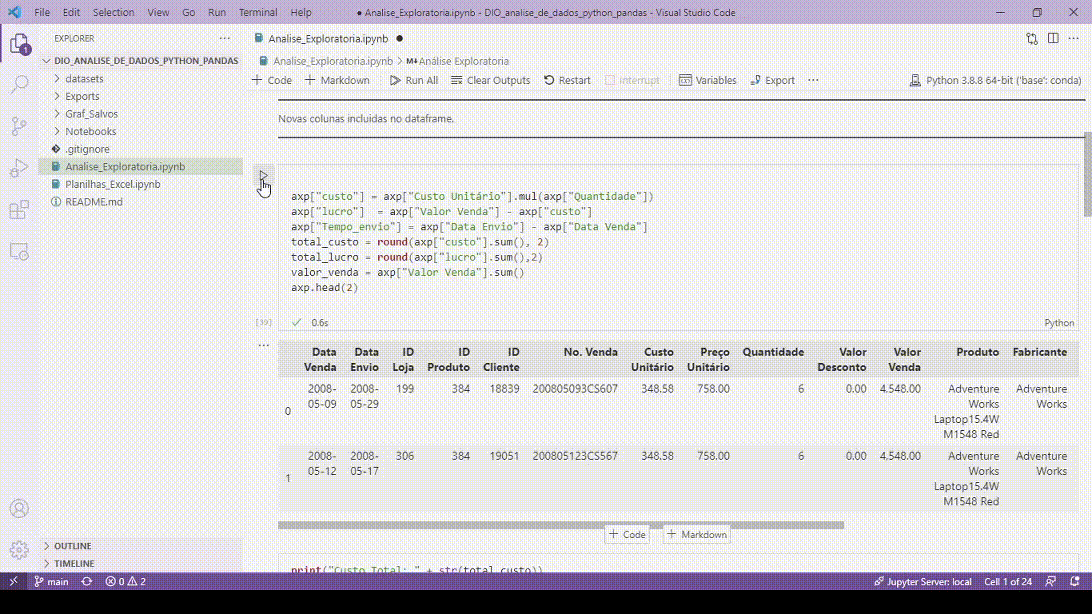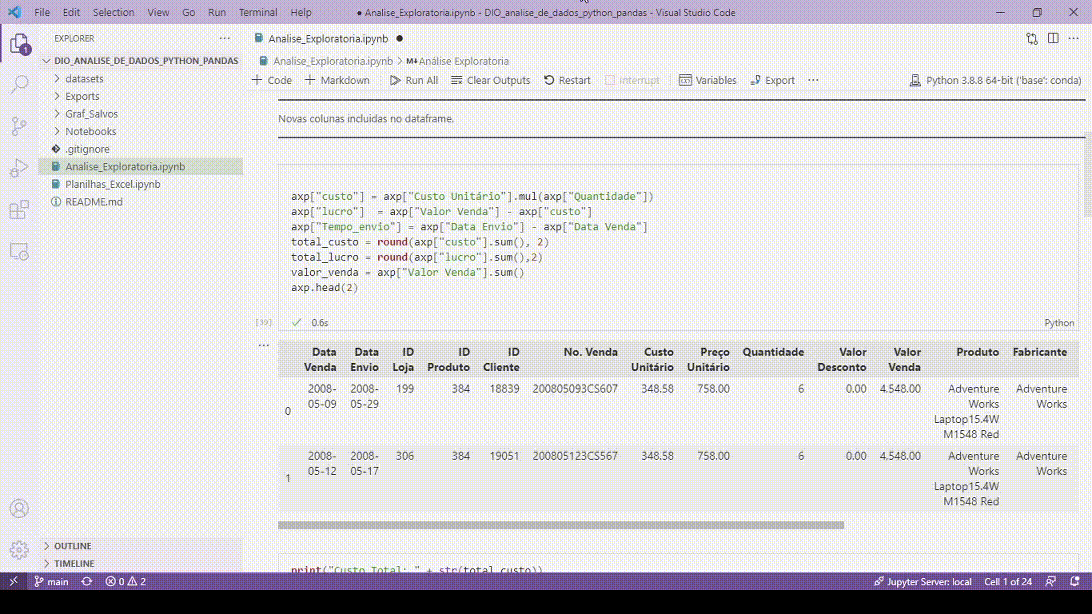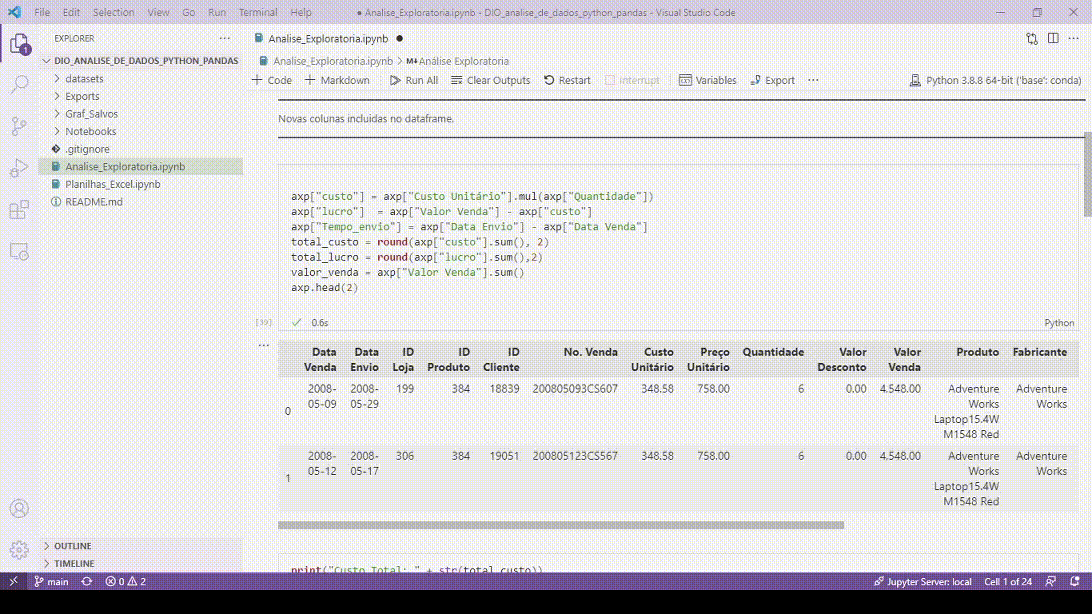
Uma das funções que eu mais gosto é a visualização das variáveis, basta clicar que abre a lista de todas as variáveis do pandas após a execução.
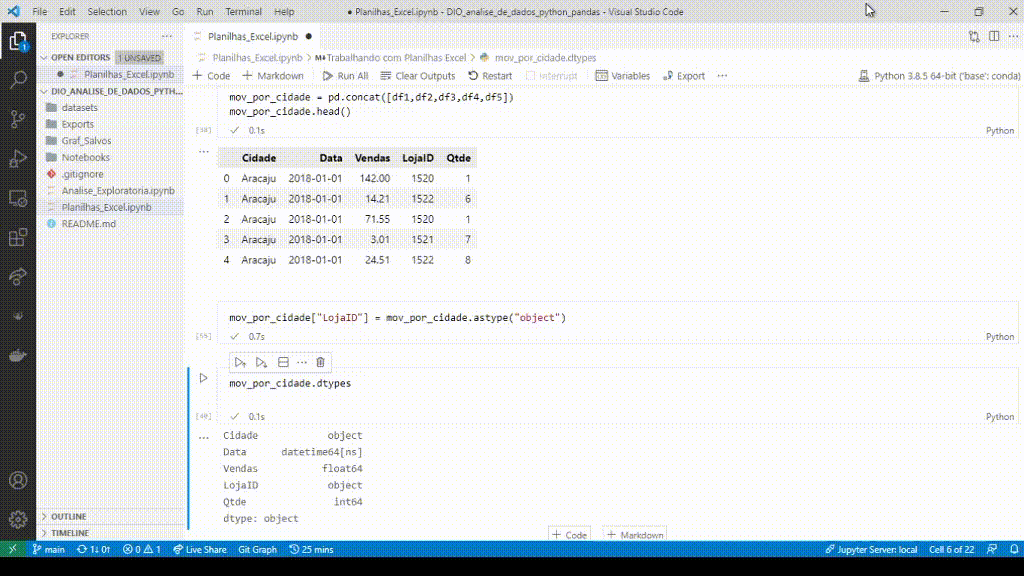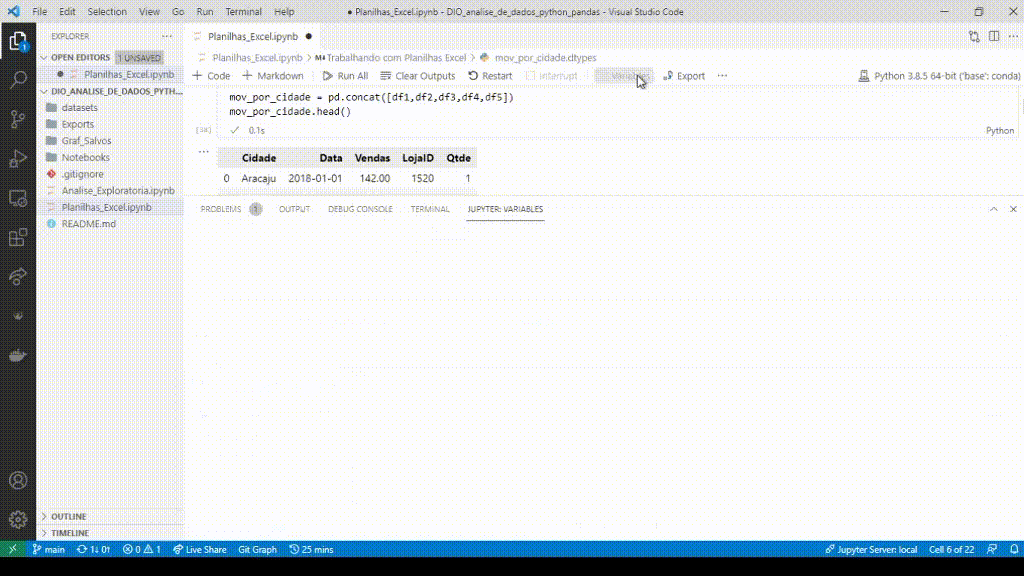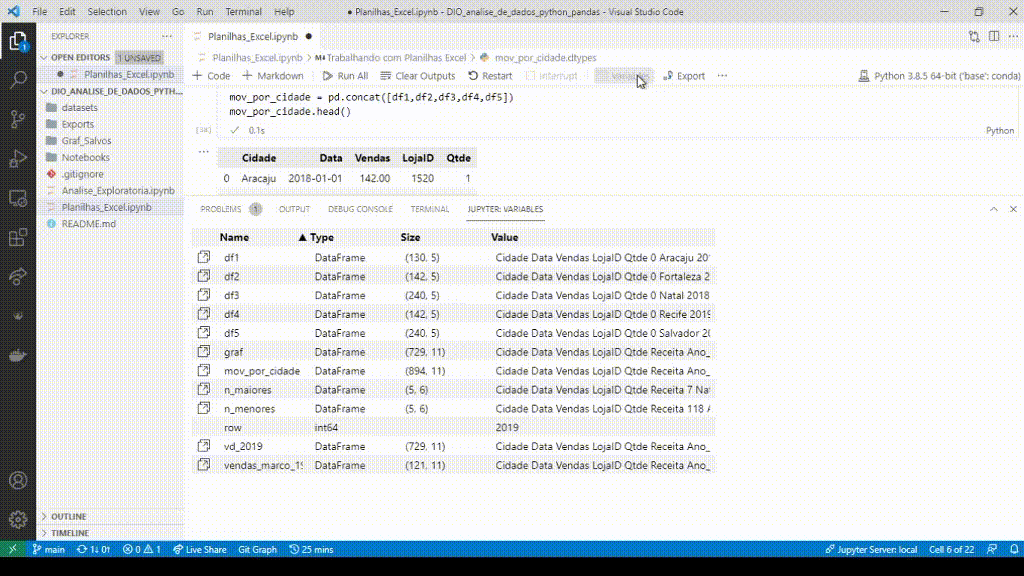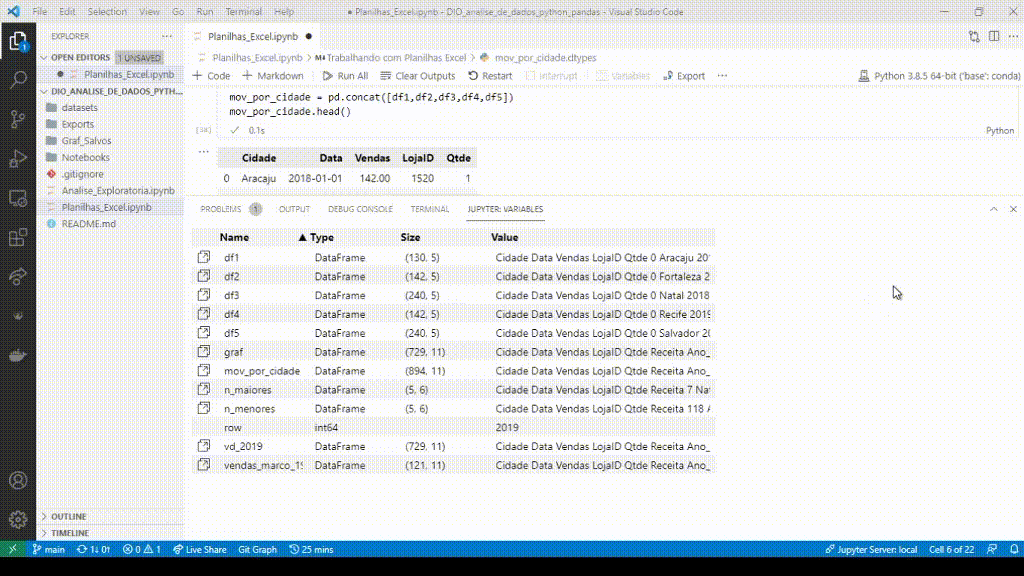
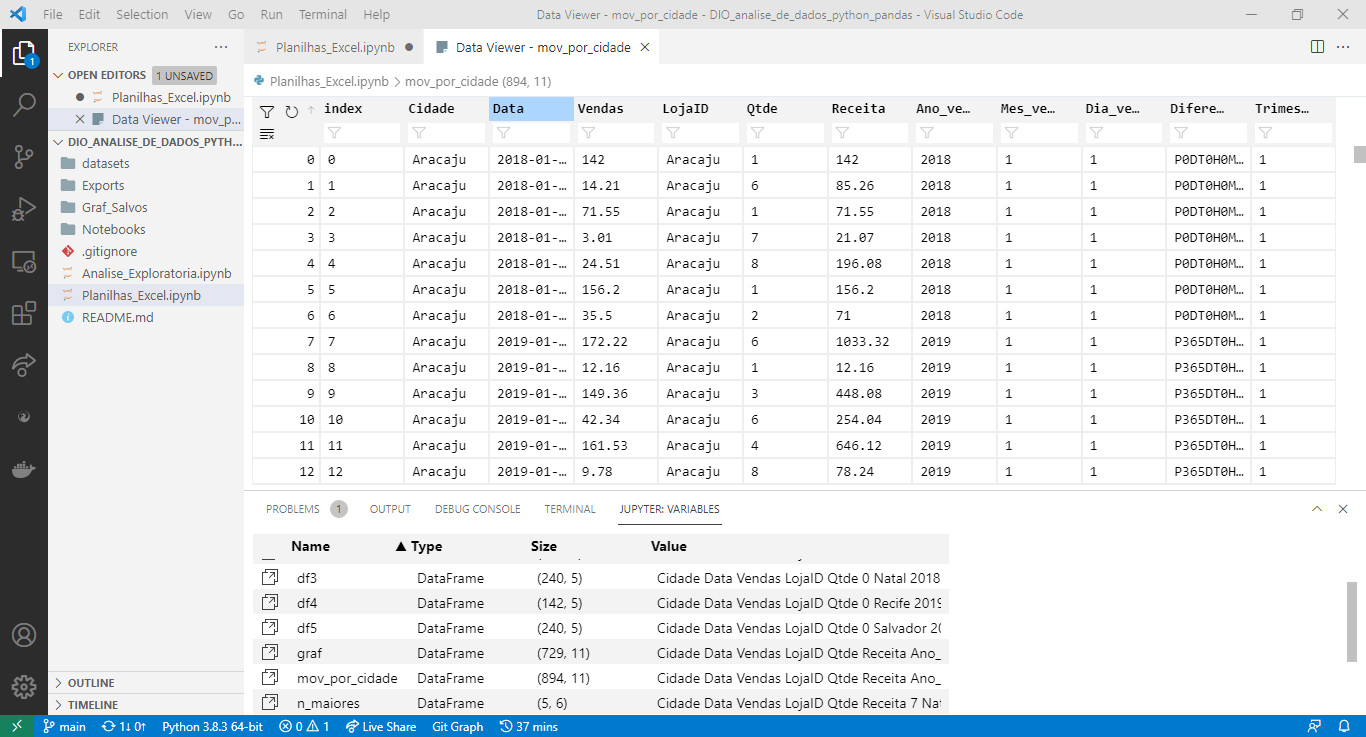
Clicando na variável abre o data viewer dela.
“Isso é tudo pessoal”, espero que esse artigo tenha ajudado vocês a criar um ambiente integrado para seus estudos na área de Data Science em uma ferramenta que já estamos acostumados.